描述性数据汇总
对于成功的数据预处理,获得数据的总体印象是至关重要的。描述性数据汇总技术可以用来识别数据的典型性质,突显哪些数据值应当视为噪声或离群点。因此,在讨论具体的数据预处理之前,我们首先介绍描述性数据汇总的基本概念。
对于许多数据预处理任务,用户希望知道关于数据的中心趋势和离中趋势特征。中心趋势度量包括均值(mean)、中位数(median)、众数(mode)和中列数(midrange),而数据离中趋势度量包括四分位数(quartiles)、四分位数极差(interquartile range, IQR)和方差(variance)。这些描述性统计量有助于理解数据的分布。这些度量在统计学界已经广泛研究。
从数据挖掘的角度,我们需要考察如何在大型数据库中有效地计算它们。特殊地,我们需要引进分布式度量、代数度量和整体度量的概念。知道我们处理的度量类型可能有助于我们选择它的有效实现。
2.2.1 度量数据的中心趋势
我们考察度量数据中心趋势的各种方法。数据集的“中心”最常用、最有效的数值度量是(算术)均值。设x1, x2,., xN是(如某个像salary这样的属性)N个值或观测的集合。
该值集的均值是
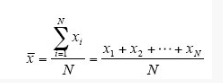
这对应于关系数据库系统提供的内部聚集函数average(SQL中为avg())。
分布式度量(distributive measure)是一种可以通过如下方法计算度量(即函数):将数据集划分成较小的子集,计算每个子集的度量,然后合并计算结果,得到原(整个)数据集的度量值。sum()和count()都是分布式度量,因为它们都可以用这种方法计算。其他例子包括max()和min()。代数度量(algebraic measure)是可以通过应用一个代数函数于一个或多个分布度量计算的度量。因此,average(或mean())是代数度量,因为它可以通过sum()/count() 计算。当我们计算数据立方体时,sum()和count()可以在预计算时保留。这样,导出数据立方体的average是直截了当的。
有时,集合中每个值xi与一个权值wi相关联,i = 1, ., N。权值反映对应值的显著性、重要性或出现频率。在这种情况下,我们可以计算

这称为加权算术均值(weighted arithmetic mean)或加权平均(weighted average)。注意,加权平均是代数度量的又一个例子。
尽管均值是描述数据集的最有用的单个量,但不总是度量数据中心的最好方法。均值的主要问题是对于极端值(如离群值)很敏感。即使少量极端值也可能影响均值。例如,公司的平均工资可能被少数高报酬的经理的工资显著抬高。类似地,班级的考试平均成绩可能因为少数几个非常低的成绩而降低相当多。为了抵销少数极端值的影响,我们可以使用截断均值(trimmed mean)。截断均值是去掉高、低极端值得到的均值。例如,我们可以将工资的观
测值排序,并在计算均值前去掉上下各2%的值。我们应当避免在两端截断的比例太大(如20%),因为这可能导致损失有价值的信息。
对于倾斜的(非对称的)数据,数据中心的一个较好度量是中位数。设给定的N个不同值的数据集按数值序排序。如果N是奇数,则中位数是有序集的中间值;否则(即,如果N是偶数),中位数是中间两个值的平均值。
整体度量(holistic measure)是必须对整个数据集计算的度量。整体度量不能通过将给定数据划分成子集并合并每个子集上度量得到的值来计算。中位数是整体度量的一个例子。计算整体度量的开销比计算上述分布度量的开销大得多。
然而,我们可以容易地计算数据集中位数的近似值。假定数据根据它们的xi值划分成区间,并且已知每个区间的频率(即数据值的个数)。例如,可以根据年薪将人划分到诸如10~20K, 20~30K等区间。令包含中位数频率的区间为中位数区间。我们可以使用如下公式插值计算整个数据集的中位数的近似值:
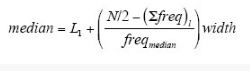
数据立方体的计算在第3、4章详细介绍。
其中,L1是中位数区间的下界,N是整个数据集的值的个数,(Σfreq)l是低于中位数区间的所有区间的频率和,freqmedian是中位数区间的频率,而width是中位数区间的宽度。
另一种中心趋势度量是众数。数据集的众数是集合中出现频率最高的值。可能最高频率对应多个不同值,导致多个众数。具有一个、两个或三个众数的数据集合分别称为单峰的(unimodal)、双峰的(bimodal)和三峰的(trimodal)。一般,具有两个或更多众数的数据集是多峰的(multimodal)。在另一种极端情况下,如果每个数据值仅出现一次,则它没有众数。
对于适度倾斜(非对称的)的单峰频率曲线,我们有下面的经验关系
mean-mode = 3×(mean-median) (2-4)
这意味如果均值和中位数已知,适度倾斜的单峰频率曲线的众数容易计算。
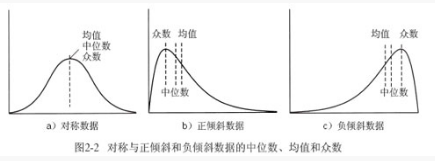
在完全对称的数据分布单峰频率曲线中,均值、中位数和众数都是相同的中心值,如图2-2a 所示。然而,在大部分实际应用中数据不是对称的。它们可能是正倾斜的,其中众数出现在小于中位数的值上(图2-2b);或者是负倾斜的,其中众数出现在大于中位数的值上(图2-2c)。
中列数也可以用来评估数据集的中心趋势。中列数是数据集的最大和最小值的平均值。中列数是代数度量,因为它容易使用SQL的聚集函数max()和min()计算。
2.2.2 度量数据的离散程度
数值数据趋向于分散的程度称为数据的离差或方差。数据离中趋势的最常用度量是极差、五数概括(基于四分位数)、中间四分位数极差和标准差。盒图根据五数概括绘制,是一种识别离群点的有用工具。
1. 极差、四分位数、离群点和盒图
设x1, x2,., xN是某属性的观测值集合。该集合的极差(range)是最大值(max())与最小值(min())之差。本节的其余部分假定数据以数值递增序排列。
在数值序下,数据集合的第k个百分位数(percentile)是具有如下性质的值xi:百分之k的数据项位于或低于xi。中位数(上一节讨论过)是第50个百分位数。除中位数外,最常用的百分位数是四分位数(quartile)。第一个四分位数记作Q1,是第25个百分位数;第三个四分位数记作Q3,是第75个百分位数。四分位数(包括中位数)给出分布的中心、离散和形状的某种指示。第一个和第三个四分位数之间的距离是分布的一种简单度量,它给出被数据的中间一半所覆盖的范围。该距离称为中间四分位数极差(IQR),定义为
IQR = Q3 -Q1 (2-5)
根据类似于2.2.1节中位数分析的推理,可以断言Q1和Q3是整体度量,IQR也是。
描述倾斜分布,单个分布数值度量(如IQR)不是非常有用的。倾斜分布两边的分布是不等的(图2-2)。因此,提供两个四分位数Q1和Q3以及中位数信息更丰富。一个识别可疑的离群点的常用经验是:挑出落在至少高于第三个四分位数或低于第一个四分位数1.5×IQR处的值。
因为Q1、中位数和Q3不包含数据端点(例如尾)信息,分布形状的更完整概括可以通过提供最高和最低数据值得到。这称作五数概括。分布的五数概括(five-number summary)由中位数,四分位数Q1和Q3,最小和最大观测值组成,按以下次序写为Minimum, Q1, Median, Q3, Maximum。
分布的一种流行的可视化表示是盒图(boxplot)。盒图体现了五数概括:
. 在典型情况下,盒的端点在四分位数上使得盒的长度是中间四分位数极差IQR。
. 中位数用盒内的线标记。
. 盒外的两条线(称作胡须)延伸到最小(Minimum)和最大(Maximum)观测值。
当处理数量适中的观测值时,值得个别地绘出潜在的离群点。在盒图中这样做:仅当这些值超过四分位数不到1.5×IQR时,胡须扩展到最高和最低观测值。否则,胡须出现在四分位数的1.5×IQR之内的最极端的观测值处终止。剩下的情况个别地绘出。盒图可以用来比较若干个可比数据集。图2-3给出在给定的时间段,AllElectronics的4个分店销售的商品单价数据的盒图。对于分店1,我们看到销售商品单价的中位数是80美元,Q1是60美元,Q3是100美元。注意,该分店的两个边远的观测值个别地绘制,因为它们的值175和202超过IQR的1.5倍,这里IQR = 40。
对于大型数据集的挖掘,盒图的有效计算,甚至是近似的盒图(基于五数概括的近似)仍然是一个具有挑战性的问题。

图2-3 在给定的时间段,AllElectronics的4个分店销售的商品单价的盒图
2. 方差和标准差
N个观测值x1, x2, ., xN的方差是
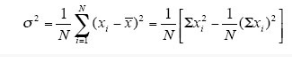
其中, 是观测值的均值,由式(2-1)定义。观测值的标准差σ是方差x σ2的平方根。
作为发散性的度量,标准差σ的基本性质是
. σ度量关于均值的发散,仅当选择均值作为中心度量时使用。
. 仅当不存在发散时,即当所有的观测值都具有相同值时,σ = 0;否则,σ > 0。方差和标准差是代数度量,因为它们可以由分布度量计算。即,N(SQL的count())、Σxi (xi的sum())和Σxi 2(xi 2的sum())可以按任意划分进行计算,然后合并提供给式(2-6)。这样,方差和标准差的计算在大型数据库都是可伸缩的。

数据分析咨询请扫描二维码






