昨天和学长聊到下周要做的数据清洗工作,心想应该很好上手吧,结果今早爬起来一问度娘,立马就被灌了整锅的毒鸡汤…某论坛上的网友甚至告诉小编,数据清洗占了他某项工作中的八成分量,是绝对的大工程…
额…好吧,尽管小编还是这方面的零基础学员,鼓捣了一整天依然图样图森破,但是在“还要多学习”的精神指引下,还是来跟大家分享一点学习中的收获吧。
前方预警:大神请绕行~
在开始今天的介绍之前,有几点说明:
1. 这次介绍的代码主要针对重复值、缺失值和字符中的空格等情况的处理;
2. 由于篇幅限制,演示中导入csv格式文件作为数据来源;
3. 请在“文件”菜单中把R软件的“当前工作目录”改为导入文件所在目录;
4. 本次使用的数据是世界银行数据库中的“国家政策和制度评估(CPIA):公共部门管理和机构集群平均值(1=低至 6=高)”数据;另外,为使清洗效果更明显,我对其做了点“手脚”,让其显得“更乱”:

那么,这么“脏乱”的数据该咋“洗”呢?具体步骤如下:
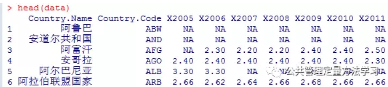
1. 读取并创建数据表。可以通过查看数据表前5行看看是否读取;
#读取并创建数据表
data=data.frame(read.csv('CPIA.csv',header =1))
#查看数据表前5行
head(data)
2. 清洗特定列的重复值。R语言的返回结果为:重复的标记为TURE,不重复的值标记为FALSE;下面以清洗“国家名称”这一列的重复值为例,其他各列依次完成;
#重复值清洗
duplicated(data$Country.Name)

#删除重复值,返回唯一值列表
data=unique(data)
#查看清洗结果
duplicated(data$Country.Name)

3. 空值清洗。
(1)如果查找数据表中的空值,则代码为:
#查找数据表中的空值
head(is.na(data),n = 264)
需要注意的是,这里的264是数据容量,R语言的返回结果依然是空值标记为TURE,非空值标记为FALSE;
(2)如果查找特定列中的空值,则代码如下(以2015年数据为例):
#查看特定列中的空值
is.na(data$X2015)
(3)处理空值的方式有两种,将空值填充为0或删除空值所在行;
#将空值填充为0
data[is.na(data)] <- 0
#删除空值所在行
data<-na.omit(data)
4. 去除特定列中字符间的空格。需要安装并加载raster包,以“国家名称”列为例;
#提取“国家名称”列
Country.Name=as.vector(data$Country.Name)
#安装raster包
install.packages('raster')
#加载raster包
library(raster)
#去除“国家名称”字段中的空格
Country=trim(Country.Name)
#覆盖原有“国家名称”字段
data$Country.Name=Country
5. 另存为新文件,供后续分析;
#保存为csv文件
write.csv(data,file="CPIA1.csv")


数据分析咨询请扫描二维码






