简单的认识一下组合分类器以及R语言对应使用函数
首先,我们大家都有学习过一系列的分类方法,例如决策树,贝叶斯分类器等,有时候分类的效果不太如人意,哪怕是参数是最优化也一样,所以这时候就需要一些提高分类准确性的方法,我们常用的就是组合分类器,它就是一个复合模型,也就是由多个分类器组合而成;个体的分类器对结果进行投票,然后对组合分类器返回的投票进行汇总,然后基于返回的结果进行预测和分类。组合分类器的结果往往比它的成员分类器更准确;一般常用的组合分类方法有bigbing,boosting,还有我比较喜欢的随机森林; 什么是组合分类?
组合分类就是把K个学习得到的模型M1,M2,...,MK组合在一起,使用给定数据集D创建K个训练集D1,D2,...,DK,其中D1用于创建M1模型,以此类推;给定一个待分类的新数据元组,每个基分类器通过返回类预测投票,它收集由基于基分类器返回的类标预测,并输出占多数的类,基分类器也会出错,当基分类器出错时不代表组合分类器出错,组合分类器基于基本分类器的投票返回类预测,因此基分类器要出错超过一半时组合分类器才会出错,并且基分类器之间是不相关的,这也就是说明组合分类器更加准确。
bagging
这个方法也叫装袋法,这个也是组合分类器的一种,它的理念在与通过自举的方法建立很多不同的模型,然后对结果取平均,其本质是使得一些较弱的模型形成一个群体对结果来投票,从而得到更精确的预测;例如,如果你是一名病人希望根据你的症状做出诊断,你可能选择多个医生,而不是一个,如果某个诊断结果比其他诊断结果出现的次数多,你可能认为这个结果是最为可能出现的诊断结果,也即是说最终的诊断结果是根据多数表决做出的;其中每个医生的权重都一样,更多的医生表决比少数医生的多数表决更为的可靠;
在给定D个元组的集合,采用有放回抽样,每个训练集都是一个自助样本,每个训练集通过学习得到一个分类模型,对未知的元组进行分类,每个分类器M返回它的分类结果,算做一票,最后得票最高的作为结果类;对连续变量则通过取平均值;
那么在R语言里面怎么使用这个方法呢?
这时候我先要装好包ipred包中的bagging函数建立回归的bagging模型;
例如
bagging(price~x1+x2,data=test_date,nbagg=20)#这里只是举例代码并不能执行;
nbagg时选择多少个rpart数
boosting
这个方法也叫提升,它和上面的方法有些类似,假如你是一位病人,你选择咨询多位医生,然而得到的结果不是一致的,这时候你就需要根据先前医生诊断的准确率。对每一位医生赋予一个权重,然后根据加权诊断的组合作为最终的结果;这就是提升的基本思想;
早提升方法中,首先权重赋予每个训练元组,迭代的学习K个分类器;学习得到分类器M1之后,更新权重,使得其后的分类器M2更关注误分类的训练元组,如元组不准确的分类,则它的权重增加,如果元组正确分类,则它的权重减少;这是希望我们能够更加关注上一轮误分类的元组;其中每个分类器投票的权重是其准确率的函数;
bagging和boosting相比
由于boosting更加的关注误分的元组,所以存在结果符合模型的过度拟合的危险,bagging则不太受这个影响,不过二者都能够显著的提高准确度;boosting往往能够得到较高的准确率;
R语言里使用的是包mboost中的blackboost函数从回归树种建立boosting模型,glmboost从广义线性模型中建立模型;
blackboost(price~x1+x2,data=test_date)#这里只是举例代码并不能执行;
随机森林也是一种组合分类器,因为每一个分类器都是一棵树,所以组合在一起就很像一个森林;每一个数都依赖独立抽样;
随机森林可以使用bagging和随机属性来选择组合来构建,
A、指定M值,即随机产生M个属性用于节点上的二叉树,二叉树属性选择任然满足不纯度最小原则,不纯度公式为
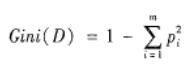
B、应用BOOTSTRAP自助法在员数据集中有放回地随机抽取K个样本集,组成K颗决策树,而对于未被抽取的样本用于决策树的预测;
C、根据K个决策树组成的随机森林对待分类样本进行分类或者预测,分类的原则是投票法,预测的原则是简单平均。
想象组合分类器中每个分类器都是一颗决策树,因此分类器的集合就是一个“森林”,使用CART算法的方法来增长树,树增长到最大的规模,并且不剪枝,用这种方式形成的随机森林称为Forest-RI,数据分析师培训
另一种形式称为Forest-RC,他不是随机地选择一个属性子集,而是选择一个属性子集,而是由已有的属性的线性组合创建一些新属性,就是由原来的S个属性组合,在给定的节点,随机选择S个属性,并且以次欧诺个[-1,1]中随机选取的数为系数相加,产生S个线性组合,并在其中找到最佳的划分,仅仅只有少量属性可用时,为了降低个体分类器之间的相关性,这种形式的随机森林才有用。
随机森林的准确率可以boosting媲美,随机森林的泛化误差收敛,所以不存在过度拟合不是什么问题;
R语言最后给我们常用randomForest包中的randomForest函数去建模;
randomForest (price~x1+x2,data=test_date)#这里只是举例代码并不能执行;

数据分析咨询请扫描二维码






