忘掉大数据之“术”,点“数”成金
在刚刚结束的两会上“互联网金融”成为了代表委员们热议的话题。从政府工作报告对互联网金融发展的表述中可以看到,金融行业新一轮淘汰洗牌不可避免。在3月9日华夏互金私董会上,多位行业内人士分析认为,互联网金融淘汰赛进入到2.0时代。金融的本质决定你能否活着,而互联网则决定你的平台能活多久。大数据已经成为许多金融企业的核心资产,通过机器学习和大规模的大数据分析,以一种完全不同的方式来更快更精准的作出决策(如金融产品推荐),为企业创造更丰盛的价值,在众多竞争对手中脱颖而出。但由于大数据行业普遍存在数据开放共享不足、基础薄弱、应用领域单一等问题,这些问题会直接影响到模型的好坏。本文由极光大数据研究院数据挖掘工程师余承乐撰写,探讨金融产品推荐中一种完美插补用户行为数据缺失的算法。
研究背景:
基于海量的用户行为数据,极光大数据可提供全行业的综合营销整体解决方案,并且在低价值数据稠密、高价值数据稀疏处理上也有一定的研究。以金融产品智能推荐为例,众所周知,数据稀疏性问题是影响推荐系统质量的一个关键因素,它会直接造成推荐的准确性不高。针对推荐系统中存在的数据稀疏性问题,最直接的解决办法就是给空缺值设定一个固定的缺省值,一般设为评分域的中间值(如7分制评分中设为4),或者设为用户对应标签所有评分的平均值,这种方法在一定程度上可以提高推荐的精度,但是并不能从根本上解决用户标签数据的稀疏性问题。
目前,已有很多专家提出了一些有效的解决数据稀疏性的方法。这些方法基本可以分为两大类,一种是在数据稀疏性不变的情况下提高已有算法的精度,另一种就是采用一些可行的方法来尽量减小数据集的稀疏性。其中有用到奇异值分解(SVD)技术,通过对输入矩阵降维来降低数据稀疏性的。也有结合奇异值分解与最近邻算法,通过奇异值分解平滑输入矩阵,然后采用最近邻算法预测目标用户的标签缺失值。但是降维通常会导致用户标签信息丢失,并且分解算法复杂度高,在标签数据极端稀疏的情况下,效果并不理想。也有通过计算项目相似度来填充标签矩阵的方法,通过项目聚类,确保在同一类用户中,所有用户的标签评分最为相似。还有提出一种基于k-means 聚类的方法,首先对用户聚类,利用同类中的平均评分来预测标签矩阵中的缺失评分,这在一定程度上解决了数据稀疏的问题。不过这些插补方法都有其局限性,并不能很好的应用于全场景。
极光研究方案:
本文将重点讲述极光大数据是怎样利用改进后的RBF神经网络算法来高效预测用户标签缺失值填充稀疏矩阵,并对最终的推荐系统产生积极作用的。
首先我们需要构建一个RBF神经网络。RBF神经网络的构建过程关键在于隐含层的设计。好的隐含层架构可以有效地提高神经网络性能,反之则会让网络性能大打折扣或者增加学习代价。隐含层的设计关键在于隐含层中心节点的选择。和传统的指定节点个数不同的是,我们设计了一种动态自适应的选择方法。首先随机确定一批中心节点,然后在此基础上运用自适应算法动态确定中心节点数。设随机选择的中心节点数目为n,每个中心节点对应的节点为ki。

这样就可以有效的解决依靠经验指定RBF神经网络隐含层中心节点个数存在的问题了。
在构建的用户标签评分矩阵中,由于用户标签数据的稀疏性,会直接影响到用户相似度的计算,造成推荐系统的推荐质量难以保证。针对稀疏矩阵的补全,我们利用已构建的RBF神经网络来预测标签评分矩阵中的空缺值,填充到原始稀疏矩阵中。

实证效果:
为了验证算法的有效性,我们采用了极光用户画像数据集进行试验。数据集通过**银行客户对其七类金融产品的购买行为做正样本,为其他客户提供相应的产品推荐列表。样本数据集由10000名用户的有效行为特征标签评分和对该网推出的七类金融产品的购买行为数据组成。根据试验需要,我们将数据分为训练集(80%)和测试集(20%)两部分。
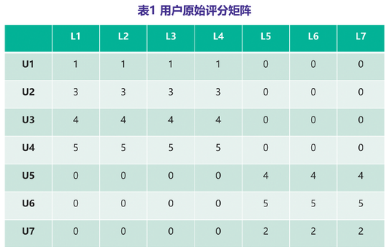
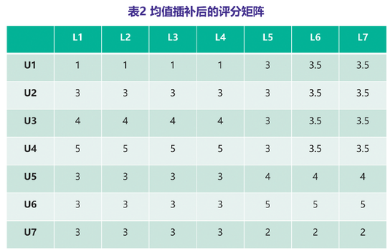
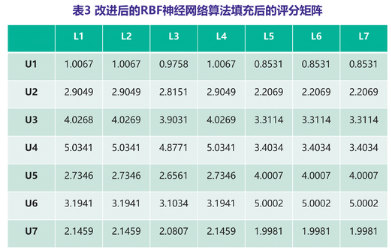
分别采用常用的均值插补和文中提出的算法进行稀疏矩阵填充,各自生成新的用户评分矩阵。这里举例展示矩阵插补的效果,U表示评分用户,L表示有效行为特征标签。表1是原始用户行为特征评分矩阵,表2是均值插补后的矩阵,表3是改进算法填充后的矩阵。
通过经典协同过滤算法对测试用户进行推荐,得出两套推荐结果。我们采用推荐系统评价指标中的多样性作为此次评价标准。好的推荐结果中要体现多样性,比如看电影,我既喜欢看格斗类的电影,同时又喜欢爱文艺,那么给我的推荐列表中就应该这两个类型的电影都有,而且得根据我爱好比例来推荐,比如我平时80%是看格斗类的,20%是看文艺类的,那么推荐结果中最好也是这个比例。可以根据物品间的相似度来计算,一个推荐列表中如果所有物品间的相似度都比较高,那么往往说明都是同一类物品,缺乏多样性。表4、5分别为两种插补后的用户推荐列表,FIN1~7分别代表消费金融类、借贷金融类、小额现金借贷类、金融中介、支付金融类、传统金融(银行类)和汽车金融共七类金融产品。

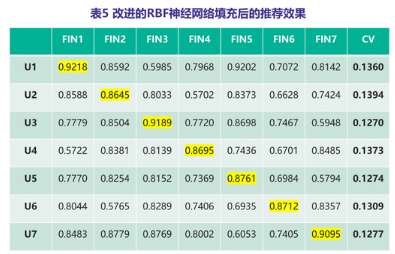
这里我们用差异系数(CV)来评价推荐的多样性。可以很直观的看到表2的差异系数远远大于表1,而且表2中对任一用户七类金融产品的推荐强弱排序与表1是保持一致的。这不仅说明了改进算法插补后的用户推荐更具多样性,而且进一步证明了改进的RBF神经网络算法既能很好的解决标签稀疏问题,又可以完整的保持用户的原始行为特征。实验结果表明,改进的RBF神经网络算法可以很好的解决用户标签的稀疏性问题,提高推荐系统的准确度,丰富推荐结果的多样性。
总结:
在金融行业中,大数据的应用范围很广,例如花旗银行通过大数据分析为财富管理客户推荐产品,美国银行利用积累的客户点击数据为客户提供有竞争的信用额度服务,招商银行利用客户行为数据定时给客户推送针对性的广告,里面有客户可能感兴趣的理财产品和优惠信息。不仅是金融领域,医 疗行业、生物技术、零售业、电商、农牧业等等,各行各业的发展都一直在依赖着数据,通过机器学习和大数据分析,决策者将会发现决定一件事、判断一件事、了解一件事不再变得困难。

数据分析咨询请扫描二维码






