如何学习基于SPSS Modeler的数据挖掘
企业想要在竞争激烈的市场中胜出,决策的速度和反应的效率尤为重要。根据调查显示,75%的企业在面临拟定策略时,常常无法获得实时且有根据的决策信息。什么样的数据、要透过什么样的方法,才能快速且实时的转变成决策时有用的信息,是现代企业所面临最迫切性的问题。数据挖掘(Data Mining)无疑是解决这些问题最有效的途径。
一、数据挖掘定义
从现有的大量数据中,撷取不明显、之前未知、可能有用的知识。
William Frawley & Gregory Piatetsky Shapiro, 1991
数据挖掘目的:建立起决策模型,根据过去的行动来预测未来的行为
二、数据挖掘流程(CRISP-DM)
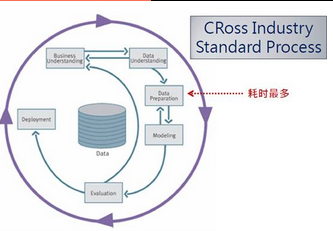
数据挖掘不是无规律可循的,在进行数据挖掘勘探工作中,我们一般遵循CRISP-DM流程。包含商业理解-数据理解-数据前处理-数据建模-模型评估-模型发布六个步骤。整个流程围绕数据为核心,其中商业理解是产生商业价值的关键步骤,数据前处理是耗时最多的步骤,建模是关键步骤。
当然,数据挖掘的流程不是至上而下的,而是循环往复的过程,比如模型评估的结果差的情况下我们可能需要返回商业和数据理解部分。
三、主流数据挖掘工具

目前主流的数据挖掘工具分开源免费和收费两大类,其中收费软件以SAS EM和IBM SPSS Modeler、Microsoft Sql Server为代表,具有权威易用、解决方案成熟等特点。开源类软件多需要编程实现,比如Python、R。具有灵活多元、可扩展性强等特点。
四、案例展示:医疗业之临床路径预测
1.商业理解
某医院搜集了200个患有同种类型疾病病人的资料。虽然得到的是同种疾病,但是不同的病人、不同的状况,需要采取不同的用药和治疗方式。我们想透过数据挖掘的方法了解到对于不同特征(血压、胆固醇、钠钾含量)的病人给予哪种药物很适合治疗康复。
2.数据理解
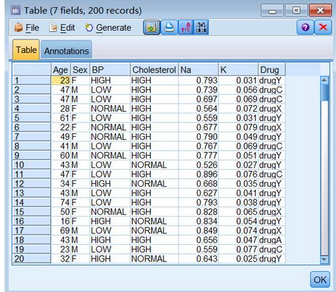
DRUG1N.CSV文件,一共包含7个变量,200个观测值。目标属性为用药类型。同时选取了可能有用的解释字段,包含年龄、性别、血压、胆固醇、钠含量、钾含量。
3.数据建模
①数据探索
了解各变量对目标变量的影响,类别型变量使用条形分布图,数值型变量使用直方图。
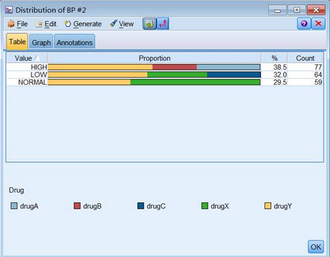
例如通过上图我们可以看出血压在影响用药上的分布,血压高中低都会有DrugY用药,而DrugA和DrugB只会在高血压的时候出现,DrugX只会在低血压和正常的时候出现,DrugC只出现在低血压,说明血压对用药的影响在目标字段上比较明显。
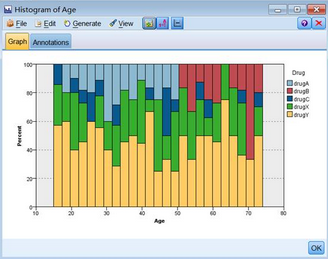
通过对年龄字段的探索,我们发现DrugY和DrugX、DrugC在各个年龄段都有分布,而DrugA只出现在大概50岁以下,DrugB只出现在年龄在50岁以上。
② 决策树建模
在这里,我们使用决策树建模的方法,决策树是一种非常常用的分类预测的方法。在IBM SPSS Modeler中我们只需要调用Modelering-C5.0进行建模。

可以看出,这是一个五层的决策树,通过决策树模型运行结果,我们即可对后续的样本进行预测。
4.模型评估
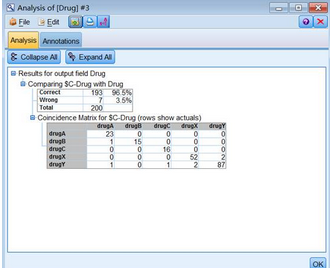
接入Analysis分析节点,运行之后可以发现模型准确率为96.5%。当然,这个是使用原数据集进行建模,实际建模过程中我们还需要用到训练集和测试集拆分的方法来进行建模和评估。

数据分析咨询请扫描二维码






