数据预处理的一些方法
现实世界中,数据集存在着不完整、包含噪声和不一致等特点,无法直接用来挖掘知识。收集数据的设备可能出故障,人为输入数据时出错或缺失,数据传输中引起的错误都将造成数据集含有不正确的属性值。数据中各个属性的单位不同,也可能造成分析过程以及预测模型的不精确。可以使用以下方法预处理数据集。
(1)删除缺失值。
(2)箱线图
R语言使用boxplot()命令绘制箱线图,箱线图也是我们常说的五数分布,通过计算 IQR=Q3-Q1,即第三个四分位数减去第一个四分位数。常用经验是剔除至少高于第三个四分位数或低于第一个四分位数1.5*IQR处的值。但在实际生产过程中,1.5只是经验带给人们的参考值,具体情况应修改这个数值。例如本次试验中,如果使用1.5这个数字,将会剔除大部分数据点,使得数据集失去意义。部分属性甚至高达10才可达到既剔除无用数据又最大限度的保留原本数据的目的。如图1所示。图中用o代替的点即为需要剔除的离群点。
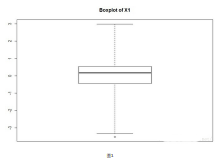
图1
(3)数据标准化/归一化
数据中心化是指讲每一项数据减去该数据集的均值。值得注意的是,标准化会对原始数据产生改变,需要保存所使用的标准化方法的参数,以便对后续的数据进行统一的标准化。数据标准化有几种不同的方法:
1. min-max标准化公式:新数据=(原数据-极小值)/(极大值-极小值)。这样能将原始值映射在[0,1]区间中的某值。
2. z-score法:将中心化后的数据除以数据集的标准差,这样做的意义是消除量纲对数据结构的影响。R语言中使用scale(x,center = T,scale =T)命令进行z-score标准化。
3. 小数定标标准化
4. 对数Logistic模式公式:新数据=1/(1+e^(-原数据))

数据分析咨询请扫描二维码






