sas评分卡之没有因变量我也能建模
在建模中,并不是什么时候都有因变量的,那么在没有因变量的情况下,我们应该怎么无耻的还要建模呢,你会说聚类啊,无监督嘛,关联规则嘛。但是我要说的我有ahp(层次分析法)
说好的,假设写了proc iml就要出综合评价法的文章,今天就来说第一个综合评价法—层次分析法,可以在维度以及数据特别紧缺的请况下建模。综合评价就是利用过往的经验给变量人为赋权重。你是不是觉得我说的很扯淡,但是我要用栗子给你明明白白的觉得我在扯淡。
层次分析法的理论
层次分析法(Analytic Hierarchy Process,简称AHP)是对一些较为复杂、较为模糊的问题作出决策的简易方法,它特别适用于那些难于完全定量分析的问题。
运用层次分析法建模,大体上可按下面四个步骤进行:
(i)建立递阶层次结构模型;
(ii)构造出各层次中的所有判断矩阵;
(iii)层次单排序及一致性检验;
(iv)层次总排序及一致性检验。
递阶层次结构的建立与特点:
(i)最高层:这一层次中只有一个元素,一般它是分析问题的预定目标或理想结果,因此也称为目标层。
(ii)中间层:这一层次中包含了为实现目标所涉及的中间环节,它可以由若干个层次组成,包括所需考虑的准则、子准则,因此也称为准则层。
(iii)最底层:这一层次包括了为实现目标可供选择的各种措施、决策方案等,此也称为措施层或方案层。
每一层次中各元素所支配的元素一般不要超过9 个。这是因为支配的元素过多会给两两比较判断带来困难。
一、构造判断矩阵:

二、层次单排序及一致性检验

判断矩阵的一致性检验的步骤:

三、层次总排序及一致性检验

理论就上面这些,来自:http://blog.sina.com.cn/s/blog_a16714bf0101dhfg.html
我要举一个例子
现在我用一个数据部门的例子来解释这个算法。譬如你们公司有很多家网点或者分行,现在是年终了,领导跟你说现在公司想给你们公司所有分行评个级,给个奖金啥的。现在给你6个维度,就是网点的,成单量,放款金额,逾期率,纯盈利金额,计划达成率,人均交单量。叫你评个级撒。那你怎么办?听我来吹牛逼。
首先第一步,你拿这几个维度给你觉得有经验的领导看下,最少找3个以上,这就要看你们平时跟领导关系好不好,然后给你6个维度重要性排名,取你找的这些领导的排名的平均数作为这个这个变量的最终排名,如果没有领导理你,那你就自己排吧。
假设我就找了我几个领导排了排名,出现下面这张表:
|
放款金额 |
成单量 |
逾期率 |
人均交单量 |
计划达成率 |
纯盈利金额 |
|
2.432 |
2.432 |
2.432 |
0.608 |
1.216 |
4.864 |
假设呢,我们公司比较小,暂时只开了四个分行,这四个分行的六大指标如下:
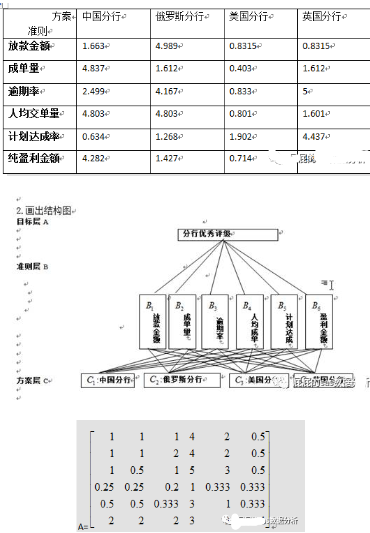
|
放款金额 |
成单量 |
逾期率 |
人均交单量 |
计划达成率 |
纯盈利金额 |
|
2.432 |
2.432 |
2.432 |
0.608 |
1.216 |
4.864 |
结合这个图看。

得到的a矩阵。
按照层次分析法的套路,我们现在要计算一个A的最大特征根及其对应的特征向量:
我们用proc iml来计算。
proc iml;
A={1 1 1 4 2 0.5,
1 1 2 4 2 0.5,
1 0.5 1 5 3 0.5,
0.25 0.25 0.2 1 0.333 0.333,
0.5 0.5 0.333 3 1 0.333,
2 2 2 3 3 1};
val=eigval(A);
vec=eigvec(A);
lamda=val[1,1];
w13=vec[ ,1];
print val vec lamda w13;
结果:

val=eigval(a)表示val是a特征值; 用vec =eigvec(a)表示vec是a特征向量。
proc iml;
CI=( 6.261296-6)/(6-1);
CR=CI/1.24;
print CI CR;
结果:
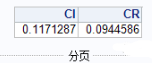
上面的理论知识中已经有公式,翻前面的理论知识看下就知道这个为什么这么算啦。
一致性检验:一致性比率CR=0.0944586<0.1,则一致性检验通过,W13可以作为权向量。

那个1.24是整理产出的,因为是6个维度对应的是1.24。以上就是我算准则层对于方案层的一个矩阵分析。
接下来我们需要作出每个方案层对于决策层的矩阵,那就是6个矩阵。
放款金额对各大分行的矩阵。矩阵怎么来呢?
|
方案 准则 |
中国分行 |
俄罗斯分行 |
美国分行 |
英国分行 |
|
放款金额 |
1.663 |
4.989 |
0.8315 |
0.8315 |
用这个数据来组成矩阵,套路跟刚才那个准则层的差不多。只是维度变了:
我做了个表格:
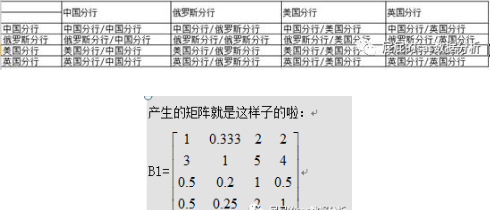
跟刚才的准则层一样,也需要算出矩阵的特征向量以及最大特征根。
proc iml;
B1={1 0.333 2 2,
3 1 5 4,
0.5 0.2 1 0.5,
0.5 0.25 2 1};
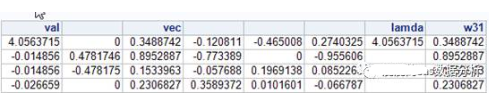
val=eigval(B1);
vec=eigvec(B1);
lamda=val[1,1];
w31=vec[ ,1];
print val vec lamda w31;
结果:
/*一致性检验:*/
proc iml;
CI=( 4.0563715-4)/(4-1);
CR=CI/0.90;
print CI CR;
结果:
一致性检验:一致性比率CR=0.0208783<0.1,则一致性检验通过,W31可以作为权向量。
一次类推算出其余的6个。

是矩阵的最大特征根。
6个矩阵的一致性检验:
一致性比率CR1=0.0208783<0.1,则一致性检验通过,W31可以作为权向量。
一致性比率CR2=0.0437436<0.1,则一致性检验通过,W32可以作为权向量。
一致性比率CR3= 0.0016285<0.1,则一致性检验通过,W33可以作为权向量。
一致性比率CR4=0.0055705<0.1,则一致性检验通过,W34可以作为权向量。
一致性比率CR5=0.0297501 <0.1,则一致性检验通过,W35可以作为权向量。
一致性比率CR6=0.0936616<0.1,则一致性检验通过,W36可以作为权向量。
将每个归一化的w系列的组合起来之后,算出权重w之后,再跟原来的准则层的w13相乘,既可以得出每个分行的得分。
proc iml;
W13={0.170,0.197,0.180,0.047,0.120,0.286};
W31={0.214,0.550,0.094,0.142};
W32={0.468,0.211,0.061,0.260};
W33={0.190,0.364,0.066,0.380};
W34={0.400,0.379,0.081,0.140};
W35={0.068,0.115,0.181,0.636};
W36={0.544,0.125,0.069,0.262};
W=W31||W32||W33||W34||W35||W36;
WW=W*W13;
print WW;
结果:
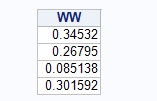
那么就是中国分行是0.34532,俄罗斯分行是0.26795,美国分行是0.85138,英国分行是0.301592。这时候我就报告领导,中国分行的是评级中的第一名。

数据分析咨询请扫描二维码






